
- AI 導入失敗率高,是因為跳過了「這個 AI 給誰用、誰負責」這個第 0 步。
- 個人外骨骼是 AI 作為個人能力延伸;企業同事是 AI 有獨立身份、由不同權限的員工指揮。兩者治理設計完全不同。
- 治理性質由「身份歸誰」決定,與技術選型(買現成、自架)無關。
- 企業同事端的核心是操作紀錄加代行紀錄,AI 執行任務時軌跡記在發起的員工身上,才能追蹤誰指派它做的。
- 不是二選一,是依場景配比。若工作現場主要透過對話流互動、且任務影響組織流程,通常偏企業同事;若主要是個人電腦工作流,通常偏個人外骨骼。
AI 導入的第一個決策:這個 AI 是給誰用、誰負責?
前陣子 Claude Code 突然紅起來,也推出了適合非技術工作者的 Cowork,陸續有朋友來問我:「我想導入 AI,要從哪裡開始?」
主流答案聽起來都對:分階段導入、評估自己做還是買現成、設定績效指標、做小規模試運行、組導入小組。每篇文章都在講不同的步驟、不同的維度、不同的階段論,但看完還是不知道怎麼開始。
我覺得這些建議都跳過了第 0 步:在問「怎麼導入」之前,要先回答這個 AI 是給誰用的。是為了賦能個體員工,強調個人的能力提升?還是希望它成為一個能與團隊協作的內部同事?
這兩條路的治理設計、權限分層、操作追蹤需求都不一樣。前面沒有考慮清楚,後面怎麼用都會覺得不順手。
AI 治理光譜:從個人外骨骼到企業同事的兩端
AI 的導入應該被看成一個光譜,兩端分別是:
- 個人腦袋的外骨骼:延伸並放大個人能力。主要由個人觸發,屬於獨立工作者的主動操作。
- 獨立自主的企業同事:使用上像真的虛擬同事,你可以傳個訊息給它,它就會回答問題或幫你做事。適合整個團隊共享的固定流程,例如產出報表並做簡單詮釋,或是操作內部系統。
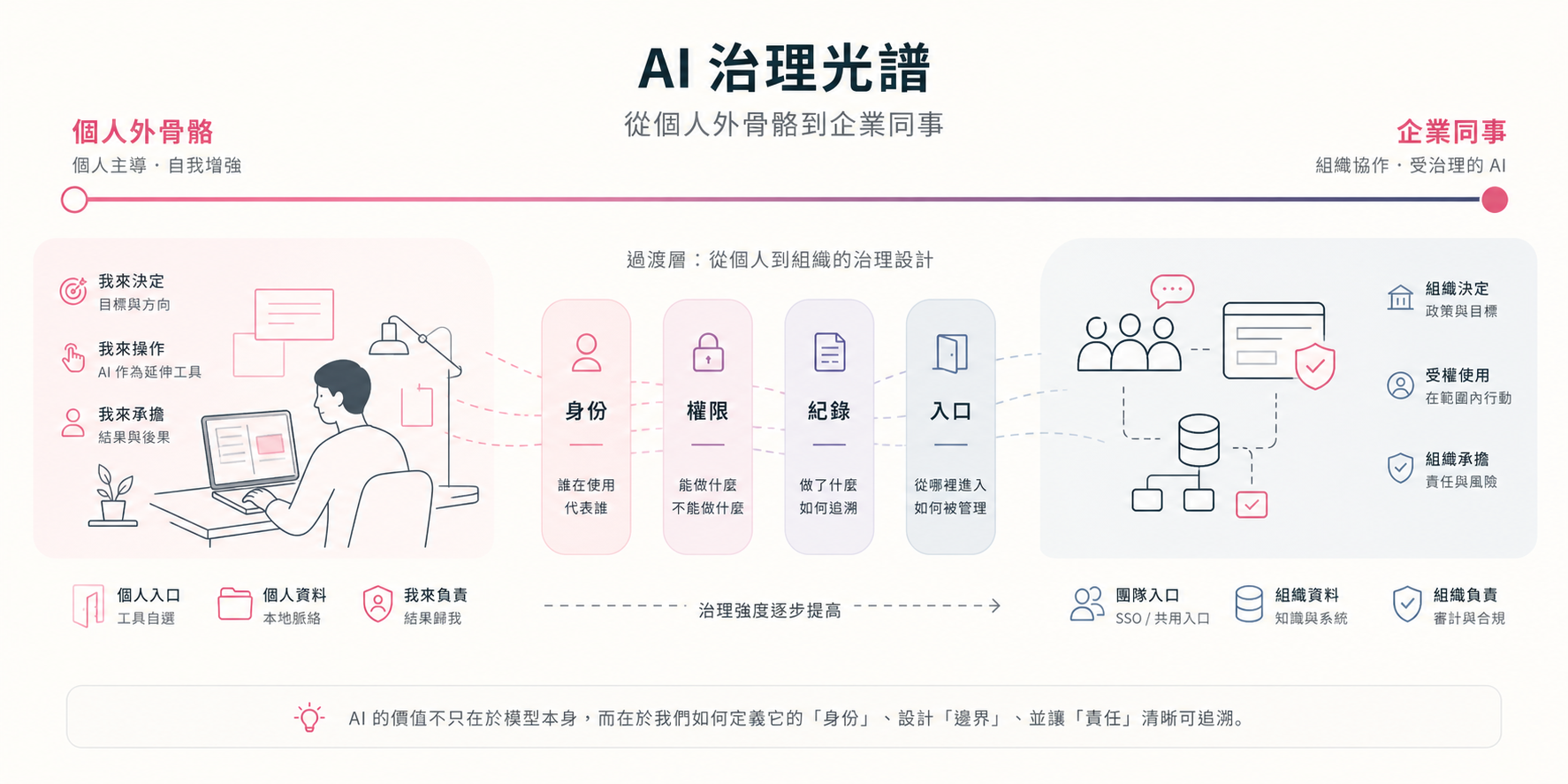
兩端的治理重點完全不同:
| 維度 | 個人外骨骼(左端) | 企業同事(右端) |
|---|---|---|
| 典型使用者 | 自由工作者、顧問、內容創作者 | 組織員工、跨部門團隊 |
| 典型工作場景 | 電腦前、多介面操作、反覆調整指令 | 手機、即時問答、通訊軟體 |
| 身份歸屬 | 員工個人帳號 | 組織機器人 |
| 工作設計 | 獨立使用者客製化設計 | 公司集中設計行為邊界 |
| 影響範圍 | 個人產出的放大 | 組織固定的工作流程 |
| 治理重點 | 個人 AI 素養、授權邊界 | 代行紀錄(聽誰的話)、權限分層 |
個人外骨骼端:放大個人能力,把 AI 全開、自己負責
以我自己使用 Claude Code 作為個人外骨骼為例:雖然權限全開很危險,但我預設都是全開的,包括讀寫、刪除檔案、終端機指令、打開瀏覽器。(在我自己的版本控管環境與可回復工作流中,由我全程監看,不建議企業導入時也預設全開。)
敢全開的前提是操作都由我主動觸發,只要走歪我都能即時介入。Claude Code 也會很明確地顯示工具使用紀錄與指令,讓我能知道它到底做了什麼:
即使全開,仍要設人工把關
但即便權限全開,有些行為需要注意。例如我不會讓 AI 直接幫我傳訊息或寄信。如果需要它準備 Email,我會下明確指令要求它儲存在「草稿」中,甚至下 prompt 的時候提供錯誤的收件人地址(eg. 自己的備用帳號),讓他就算手滑也不會寄出錯誤的信件。
外骨骼端的治理重點不是把 AI 鎖死,而是顧好個人的 AI 素養,並對不可逆的操作設人工把關(關於一些 Hook 或 Harness 可以在之後的文章分享)。
但企業導入不能假設每位員工都有同樣的 AI 素養、風險意識與即時介入能力,於是可以從另一個角度切入——設計企業控管的 AI 同事。
企業同事端:共享 AI 流程,操作要留下「誰指派」的軌跡
當 AI 從個人外骨骼變成企業同事時,治理重點從顧員工的 AI 素養,變成顧組織能不能追蹤軌跡。原因是:
- AI 帶著自己的權限執行任務
- 操作對象是組織的帳務、庫存、人事
- 你需要知道「誰指派它做的」,不只是「它做了什麼」

沒有 AI 同事之前,每筆庫存異動都對應一個人名。這是治理的基線。
把固定流程交給 AI 同事執行的瞬間,紀錄上的「誰做的」會塌成單一身份:

把固定流程交給 AI 同事執行後,速度上去了,但操作人全變成「MOJO 機器人」。紀錄上失去「誰負責」的線索。
這就是「代行紀錄(on behalf of)」要解決的問題。AI 執行,但軌跡記在發起人身上:

代行紀錄補回那條線:AI 執行,但軌跡記在發起人 PW 身上。這樣就能清楚知道是誰指揮這次操作。
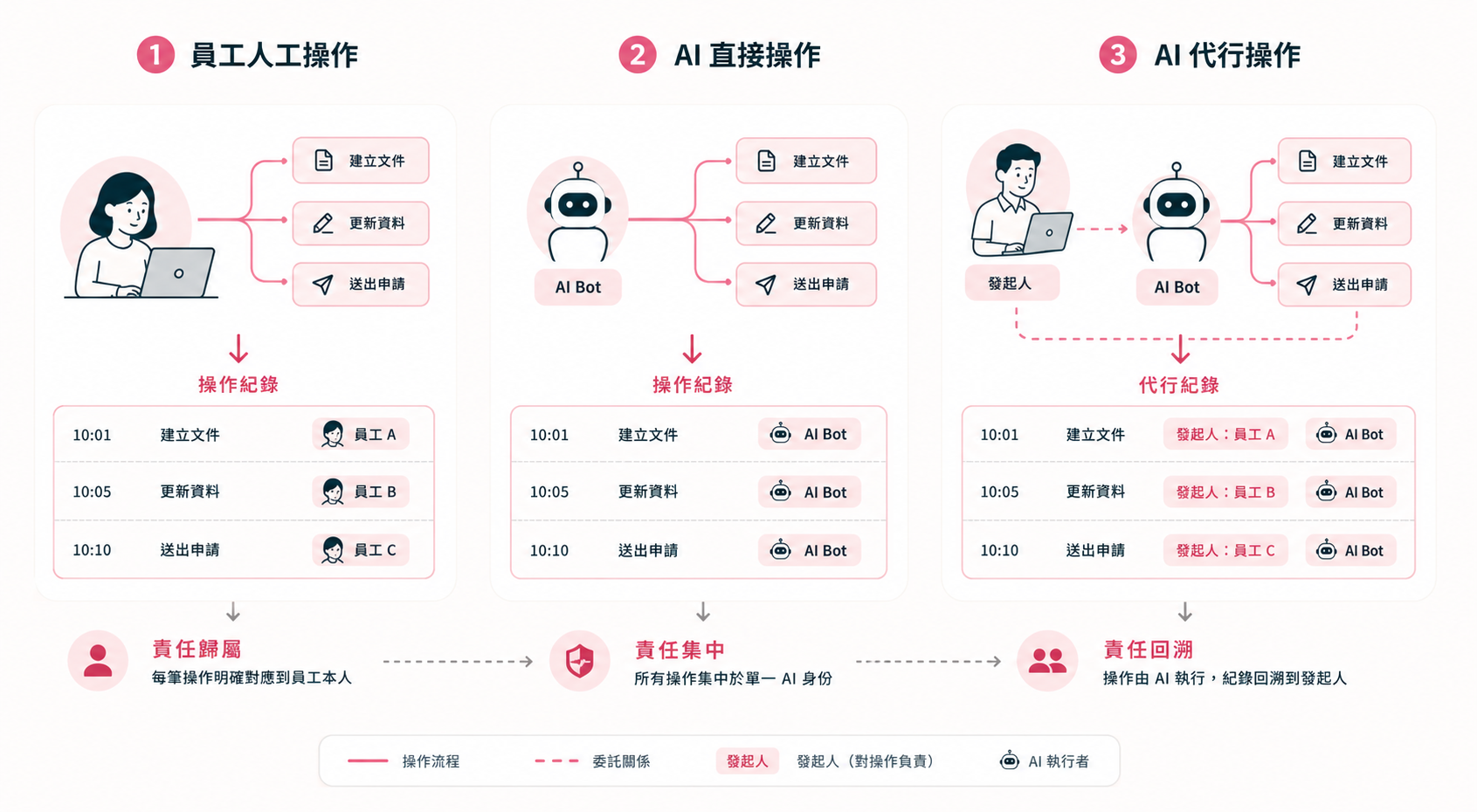
不是究責,是看誰需要協助
操作紀錄上看到某個員工反覆觸發某種失敗操作,對我來說不是「他做錯了」,是「他需要哪種訓練」或者工具設計需要調整的早期訊號。這是賦能的核心:把使用資料變成下一輪設計的依據。可追蹤不是為了監控或究責,而是為了讓組織能持續學習與迭代。
AI 治理不是二選一,是依工作場景與流程配比
光譜兩端看似對立,但實作上不是選一個,而是依場景配比。
使用者平常的工作場景
導入新工具時最大的阻力,不是工具強不強,是跟原本習慣的距離。
- 若工作現場主要透過手機、群組等通訊軟體互動,且任務會影響組織流程(如餐飲現場、第一線客服等),就更適合偏企業同事端,讓 AI 像一位更受掌控的同事。
- 若工作現場以個人在電腦前的多介面操作為主,且結果主要影響個人產出(內容創作、行銷、系統操作),就更適合偏個人外骨骼端,將 AI 接進工作流放大個人能力。
流程的統一性需求
獨立工作者每個人產出強,但跑部門共同流程時,每人都有自己的工作流,版本難管控、產出難統一。
對非技術團隊來說,程式碼版本控管工具(Git)未必是第一入口。更實際的是把共享的 context、SOP、工具版本與操作入口集中管理,讓整個團隊都從同一個「共用的 AI 同事」進入流程,再由技術管理者在背後維護版本。這樣才能確保針對同一份文件、同一個產出物,整個團隊使用的是同一個系統版本,不會因個人環境差異而產出不同結果。
兩個案例:同一個顧問,配比不同
夢酒館:從企業同事端入手
酒館員工平常都在營運第一線,不太有時間打開電腦,大多用手機操作。他們習慣的是直接「問同事」。
既然大家上班已經會問 ChatGPT、Gemini 問題,我就為他們設計一個「企業同事」角色,讓他們維持原本的習慣(手機加對話),只是這個 AI 更受我們掌控。同時設計專用的「行為規範模組」(Skills)約束 AI 的行為,碰到計算一定要跑 Python,並教育員工:
「只要看到它在計算,就要檢查它有沒有真的執行 Python。」
員工不需要先理解 AI 怎麼運作,就能享受到 AI 的好處。等到大家熟悉了,再慢慢教個人化使用。
電商朋友:加裝個人外骨骼
電商朋友平常操作就是在電腦前面。對他來說,直接讓 AI 接進電腦工作流(Claude CoWork),跟他原本習慣最接近,導入摩擦力最低,這完全符合他的使用場景。
配比的設計重點
所以兩端不是二選一,是依場景配比:
- 聊天室加組織流程:往企業同事端走(夢酒館)
- 個人電腦工作流:往個人外骨骼端走(電商朋友)
- 多人共用流程:這要看個人操作者的能力和素養。決定個人掌控度和 Agent 行為的交互設計。
真正要決定的是每個場景該偏哪一端,不是只接選好一個極端就好。
從啟動流程的位置,思考你的團隊該怎麼配比
如果正在思考自己的場景該選哪一端,可以嘗試思考「流程由誰啟動?」
是使用者主動指引 AI 工作,還是依賴系統設計聽 AI 領導?前者偏個人外骨骼,後者偏企業同事。
這題答完,你的場景在光譜上的位置自然會浮現。
在問「該用哪個工具」之前,先回答「這個 AI 給誰用、誰負責」,後面的選型才會有清楚的判準。
如果你正在嘗試 AI 導入,歡迎找我聊聊。我也會持續在實際運行的系統上做這些設計實驗跟大家分享。