
- 多數 AI 工具只是把 AI 包進更漂亮的 UI,沒有為 agent 設計工具。
- AI 時代,工具的第一個使用者不再是人類 — 給 AI 用 CLI、給人用 HTML。
- 用 SERP clustering 驗證:演算法做候選、人類做最後判斷的分工可行。
- AI-first 工具的核心不是介面更華麗,是重新思考誰在操作。
從去年剛到台北,就一直想要好好寫部落格,整理自己的思考、留下一些累積。但就像每次學煮飯都會花一堆時間研究鍋子,文章都沒寫,反而看了一堆開源框架跟 SEO 教學。
一開始只是單純去理解寫部落格或網站周邊需要哪些技能,後來我慢慢發現,我在研究怎麼設計自己 AI 的 context 時,SEO/GEO 其實是在研究內容如何進入別人的 AI context。
在 AI 時代,所有文字都可能變成某個人的 AI context。你的文章如果更容易被搜尋引擎理解、被 AI 摘要引用、被他人的 AI 工具載入,那它就不只是「一篇被看見的文章」,而是可能成為別人思考過程中的一段 prompt。
想著想著,我後來又掉入了另一個兔子洞,如果 SEO 是靠數據研究,AI 又可以幫我們收集跟操作工具,那大家寫出的文章還有哪裡可以差異化?人類應該在哪一個節點進場?
對我來說,後來就變成一個拿 SEO 當案例的介面實驗。
多數「AI 工具」只是把 AI 包進更漂亮的介面
SEO 是一個很適合做 AI-first 工具實驗的場域。它的資料量夠多、流程相對清楚、不像平常以前在酒吧的時候,很多東西都還是要靠現場的直覺感受來累積(總不可能每個客人都叫他填問券留資料)。
更重要的是,SEO 的研究對象本來就是演算法。當我們研究搜尋結果時,其實是在猜 Google 如何理解 query、如何判斷搜尋意圖、如何排列它認為最好的答案,那只要是 Google 演算法做得到的,我相信我們也有能力靠自己的演算法實驗努力逼近。
查了很多相關工具,發現很多所謂的「AI 幫你做 SEO」,其實只是把 prompt 包進一個更漂亮的 UI 裡。介面變了,但如果背後沒有資料來源、沒有穩定的計算和流程,那他提供的資訊,往往跟我們直接去問 ChatGPT 沒有本質差別(甚至可能比不上我們自己隨手搜尋然後靠直覺猜測)。
我想做的不是這種「把 AI 包裝起來」的工具,而是盡量讓工具真的有資料支持,能幫人處理那些單靠 prompt 不容易穩定完成的工作,真正由演算法計算,AI 做語意合成的工具。
不過如果只是要做 demo,平常很難隨手取得足夠的資料。SEO 剛好相反:它有大量公開結果、有相對清楚的流程,也有早就打包好的 API 工具,所以很適合拿來實作這類 AI-first 工具實驗。
SEO 研究最大的隱形成本是工具與介面切換
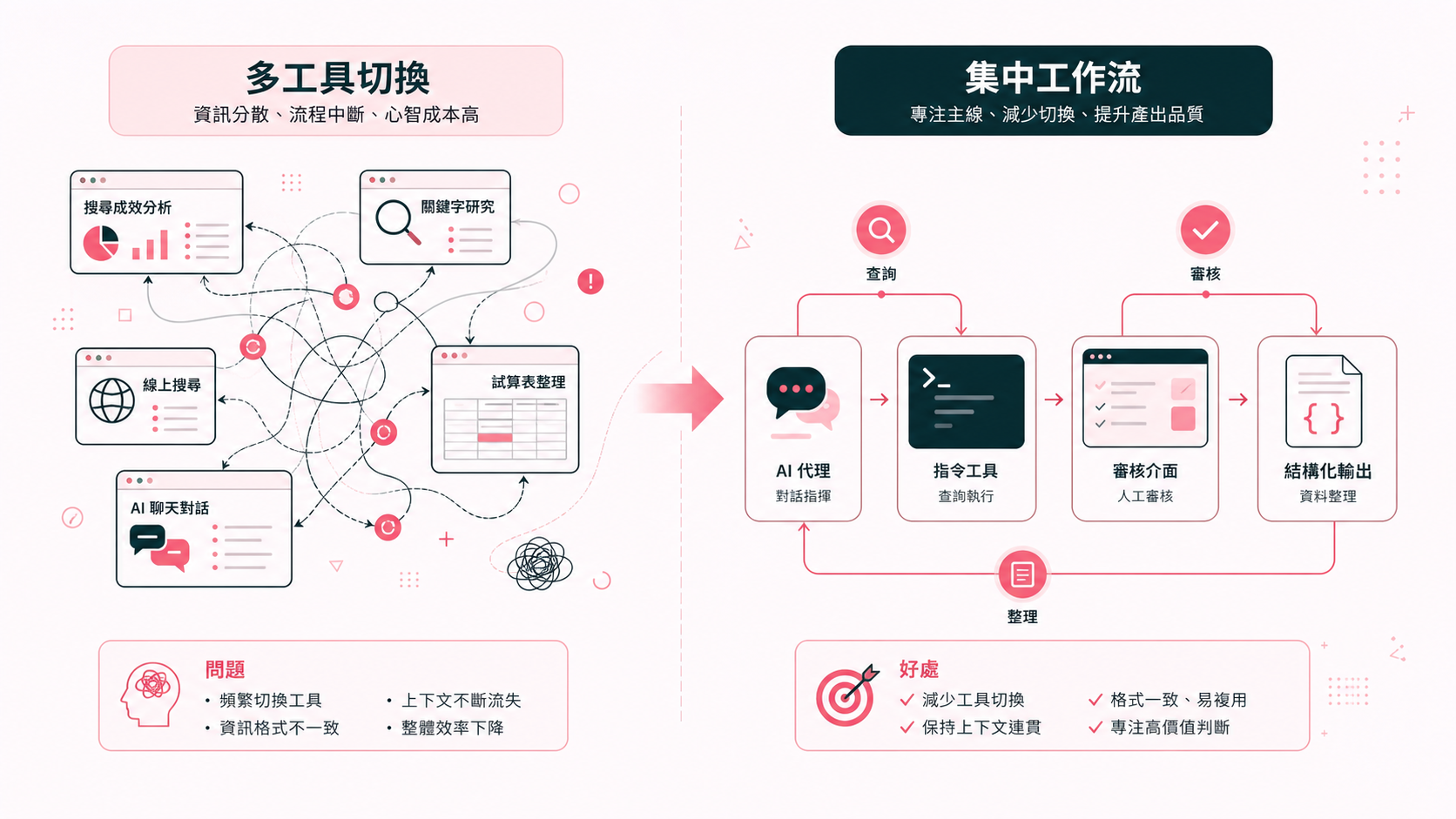
聽過一些課程後,我第一個感受到的不是 SEO 難不難,而是工具切換很累。
一次關鍵字分析就要在 Search Console 看機會、去關鍵字工具查搜尋量、無痕模式翻好幾頁、比較標題與結構、整理到 Google Sheet,再回到 Claude Code 請 AI 歸納。
每換一個畫面,就要重新把上下文裝回腦袋。資料本身不一定複雜,但切換太多次就跟 AI 一樣,上下文空間不足就會當機。
我平常最常待的工作環境是 Claude Code。寫文章、整理研究、做小工具、看資料,我幾乎都在這裡完成。所以我開始想:如果 SEO 研究可以盡量留在 Claude Code 裡完成,可能會是更適合我的方法。
後來很快發現,問題不只是「能不能留在 Claude Code 裡」,而是:當 AI 已經能替我跑工具之後,人類要怎麼在中途跟 AI 互動,介入、修正這些結果?
AI 時代,工具的第一個使用者不再是人類
一般做工具,直覺會先想 GUI:做一個網站、放幾個表單、按鈕、圖表,讓使用者自己操作。
但我這次想反過來。既然我的主要工作環境是 Claude Code,那工具第一個服務的對象其實不是人類,而是 AI agent。
也就是說,我不一定要先做一個完整漂亮的產品介面。我可以先把重複工作封裝成 CLI(之後可以也包成 MCP),讓 Claude Code 去呼叫。
AI 負責跑查詢、整理結果、讀取 JSON、接續分析。人類不需要記指令,也不需要在每個工具之間手動搬資料。
但純 CLI 很快就碰到需要人類的地方了,SERP clustering 不是只有算出結果就好。某兩個關鍵字被分在同一組,從 URL 重合度看可能合理,但跟文章想說的可能並不一致。這種判斷需要能快速視覺化,需要可以調整,需要讓人保留最後決定權。
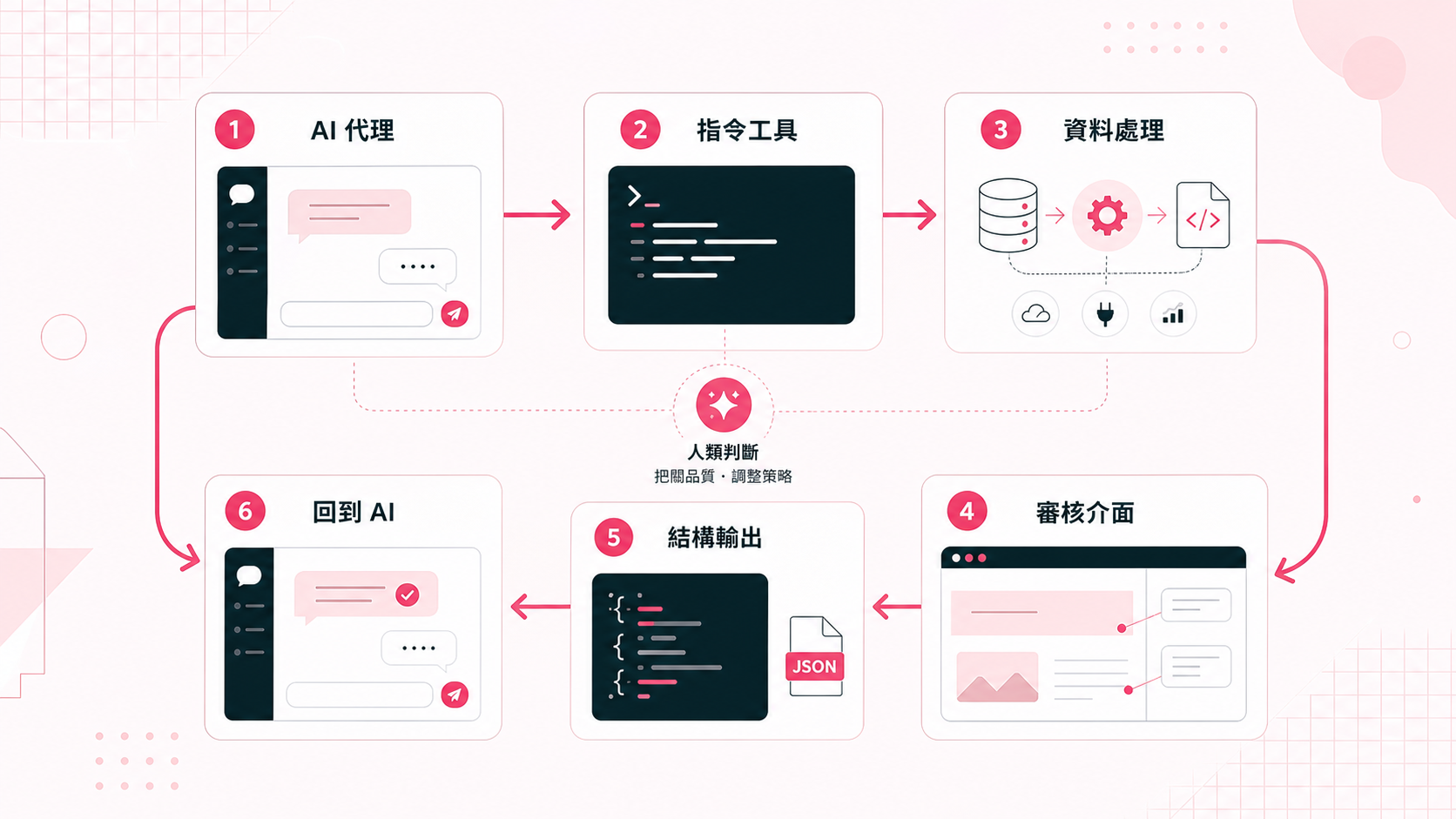
所以這個工具後來變成一個混合流程:
Claude Code 呼叫 CLI → Python 做分析 → 產生 HTML review UI → 人類調整 → 存成 JSON → Claude Code 讀回來繼續工作
這就是我現在自製工具最喜歡的 pattern:AI 做所有粗活,人類只要做判斷。
用演算法做候選、人類做最後判斷:SERP clustering 案例
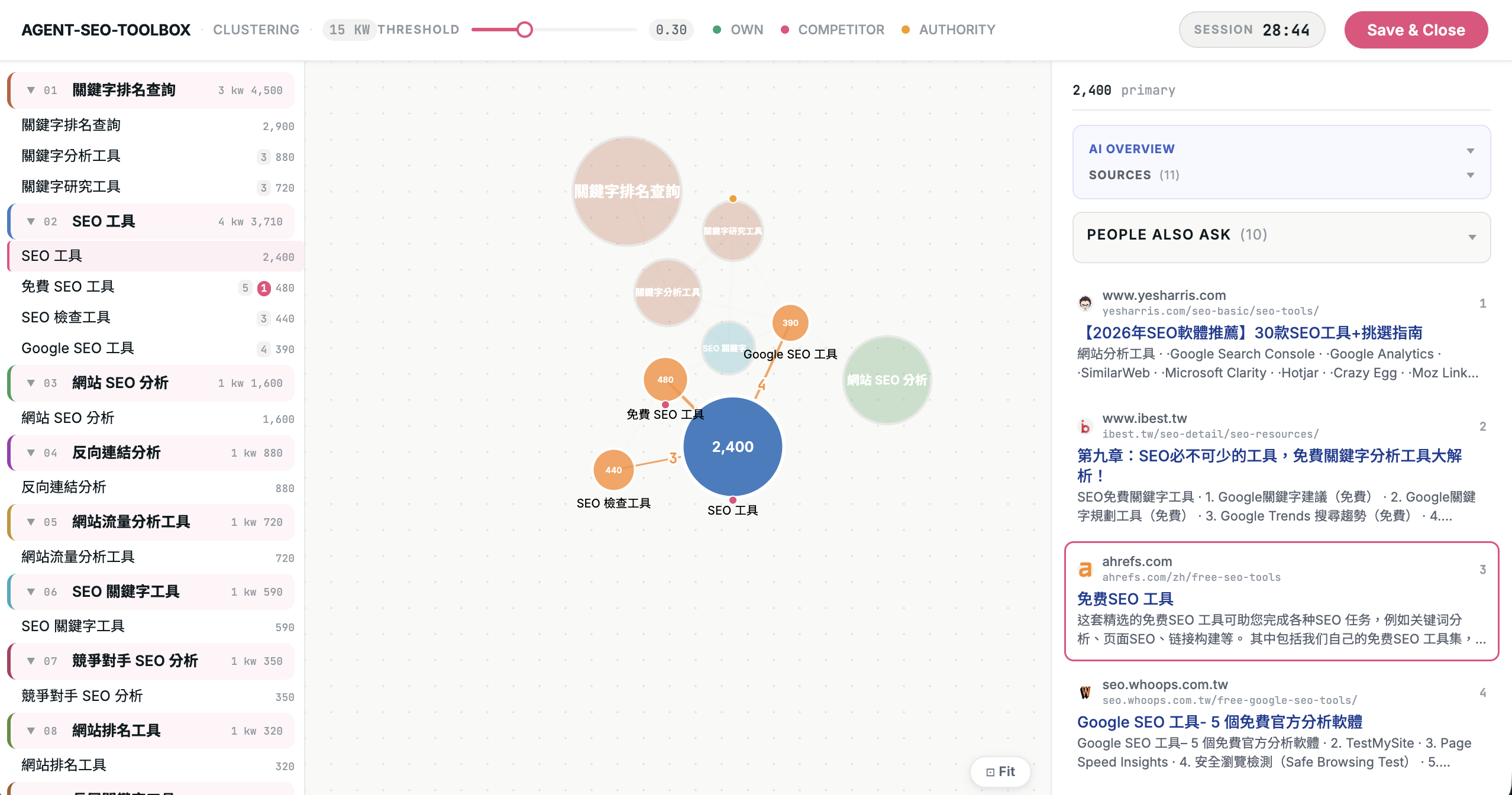
我第一個拿來驗證這套 workflow 的案例,是 SERP overlap clustering。
它解決的問題是:一批關鍵字裡,哪些字其實應該寫在同一篇文章(分散的話會互相搶流量)?哪些字雖然看起來相近,但 Google 認為它們是不同搜尋意圖?
我的做法是用 DataForSEO 抓每個關鍵字的 Organic top 10,再計算兩個關鍵字之間的搜尋結果的重合度。重合越高,代表 Google 眼裡它們是越相近的意圖;重合越低,則比較可能需要拆成不同主題。
接著工具會產生分群結果,並推一個互動式的頁面到瀏覽器。
這個介面不是要取代 AI,而是讓人類留在判斷迴圈裡。
我可以調整分群閾值,也可以點某個 keyword,看它的 SERP、AI Overview source,再用拖拉去重新分組(演算法會阻止我把不符合閾值的歸再一起)。
如果我們自己要寫文章,有些關鍵字雖然在演算法眼中屬於同一群,但放到實際內容策略裡,不一定真的是最適合寫在一起的主題。它可能和我們真正想談的角度有些出入,也可能競爭太強,以目前網站的條件根本不值得硬搶。
也因為這樣,我才會覺得 review 這一步不能省。clustering 很適合交給演算法先整理出候選答案,但最後的內容判斷,還是要讓人留在迴圈裡。
確認後按存檔,結果會寫回 JSON。Claude Code 再讀取這份 JSON,繼續幫我整理內容策略、文章角度或下一步研究。
這個設計對我來說很重要,因為我不認為可以把判斷全部交給 AI,但也不想每一步都自己手動查。比較理想的狀態是:重複、耗時、容易標準化的部分交給 API、腳本和 AI;需要品味、商業理解和策略判斷的地方留給人。
HTML 是讓 AI 跑工具、讓人類做判斷的最好中介
做完這個流程後,我才看到 Anthropic 工程師 Thariq 寫的文章《The Unreasonable Effectiveness of HTML》。
讀完覺得很有趣,因為他提到的方向跟我做這個工具時的直覺很像:讓 Claude Code 產生 HTML,讓人透過瀏覽器操作,再把結果交回 Claude。
這件事讓我更確定,HTML 在 AI agent workflow 裡可能會變成一種很重要的中間介面。CLI 對 AI 很友善,HTML 對人類更友善,而且還可以按需生成,不用像以前的 GUI 只能遵照固定的流程去運行;兩者接起來,剛好就能把「自動化」和「判斷」放在各自適合的位置。
AI-first 工具的核心問題:誰在操作?
嘗試設計 Agent-first 工具一陣子之後,我越來越覺得:AI-first 工具不是把介面做得更華麗,而是重新思考誰在操作。
如果是 AI 在操作,那工具要給 AI 好呼叫;如果需要人類判斷,那就短暫生成一個人看得懂、改得動、能存回結構化資料的介面。
SEO 剛好是這套設計的好實驗場 — 工作裡有大量重複查詢、比較和判斷,而且結果可驗證。
如果你對這種人機協作的工具設計感到好奇,歡迎聯絡我試用和交流。

