
- SERP overlap clustering 解決的是「搜尋結果彼此像不像」,但還沒有解決「內容結構長什麼樣」。
- Heading Clustering 想回答的是:高排名文章通常談哪些子題,以及這些子題如何自然聚在一起。
- GEO 的問題更難,因為 query 比 keyword 更接近自然語言,也更容易出現微小差異。
- 我目前的假設是:可以先用 embedding 對 query 做 clustering,再去比較組內與組間的 SERP、AI 回答、AI Overview 與引用來源差異。
- 這篇是想法紀錄加 PoC 筆記,不是完成報告;參數還會再調,之後我也會直接用一篇部落格做實驗。
我在做 agent-seo-toolbox 的 SERP overlap clustering 時,慢慢意識到一件事:光知道哪些關鍵字應該被分在一起,其實還不夠。
SERP overlap clustering 解決的是一個很實用的問題:Google 是否把這些關鍵字視為相近搜尋意圖?如果答案是,那它們可能值得被放進同一個內容群組裡。
但接下來還有兩個問題沒有被回答:
- 如果已經知道這些字應該放在一起,那高排名文章通常會怎麼展開這個主題?
- 如果到了 GEO 時代,query 不再只是 keyword,而是各種自然語言問題,那我們又該怎麼整理它們?
這篇就是從這兩個問題出發。
我想先說清楚:這篇還不是完成報告,比較像想法紀錄加 PoC 筆記。我現在已經做出一些可看的 prototype,也真的跑出一些 clustering 結果,但演算法參數、命名方式、noise 處理和驗證方法都還在調整中。
從 Keyword 到 Structure
SERP overlap clustering 比較像是把「搜尋結果彼此有多像」這件事算出來,但它還沒有直接告訴我:這個主題的內容結構應該長什麼樣。
如果我要真的寫一篇文章,我還是會想知道:
- 高排名文章通常談哪些子題?
- 哪些 heading 其實在不同文章裡反覆出現?
- 哪些說法雖然文字不同,但語意其實很接近?
這也是我開始想做 Heading Clustering 的原因。
如果 Google 本來就是用演算法在做排序判斷,那我在研究內容時,也會希望盡量用一套可以重複驗證的演算法來幫我整理訊號,而不是每次都只靠人腦憑感覺猜測。
人腦很適合做最後判斷,但如果前面的整理完全靠人腦,結果就會很容易被當天的狀態、經驗偏差或注意力影響。這也是我會一直想把這些研究過程慢慢工具化的原因。
Heading Clustering
我目前的想法很簡單:不要一開始就把整篇文章全文丟進模型,而是先從比較乾淨、比較接近作者判斷的地方開始。
對我來說,那個地方就是 heading,特別是 H2 / H3。
因為如果一篇文章能排到前面,那它怎麼切主題、怎麼安排段落、怎麼命名小節,本身就已經是一種信號。全文裡會有很多噪音,但 heading 通常比較接近「作者認為這篇文章該談哪些事」。
因為如果一篇文章能排到前面,那它怎麼切主題、怎麼安排段落、怎麼命名小節,本身就已經是一種信號。全文裡會有很多噪音,但 heading 通常比較接近「作者認為這篇文章該談哪些事」。
目前我在 seo-clustering-experiment 裡,已經把這條 PoC 管線實作到可以反覆跑的程度:先抓 SERP 裡的文章,再抽 H2 / H3、做 embedding、用 UMAP 降維,再交給 HDBSCAN 分群,最後再做命名和視覺化。
所以目前的實驗方向比較像這樣:
- 先抓特定 query 的高排名文章
- 抽出文章裡的
H2 / H3 - 用 embedding 把這些 heading 轉成向量
- 做 clustering,看看哪些 heading 會自然聚在一起
- 再回頭命名這些 cluster,理解高排名內容常見的子題結構
這不是要讓 AI 直接自動幫我寫大綱,而是想先整理出:Google 現在已經驗證過的內容輪廓大概長什麼樣。
我目前特別有感的幾個點是:
- 只做 baseline clustering 還不夠,UMAP 降維 對分群品質有很大影響
- embedding 模型不是越大越好,而是要看它跟後面的 clustering 管線合不合
- 只靠 LLM 幫 cluster 命名會有風險,所以需要一些比較機械、可對照的方法一起看
- site chrome、導覽列、模板語句這類 noise,不是直接丟掉就好,而是要想辦法系統化處理
下面這張就是我目前已經做出來的 heading clustering prototype。它不是最終答案,但至少讓我開始能「看見」一個 query 群組裡,高排名內容常見的子題是怎麼聚在一起的。
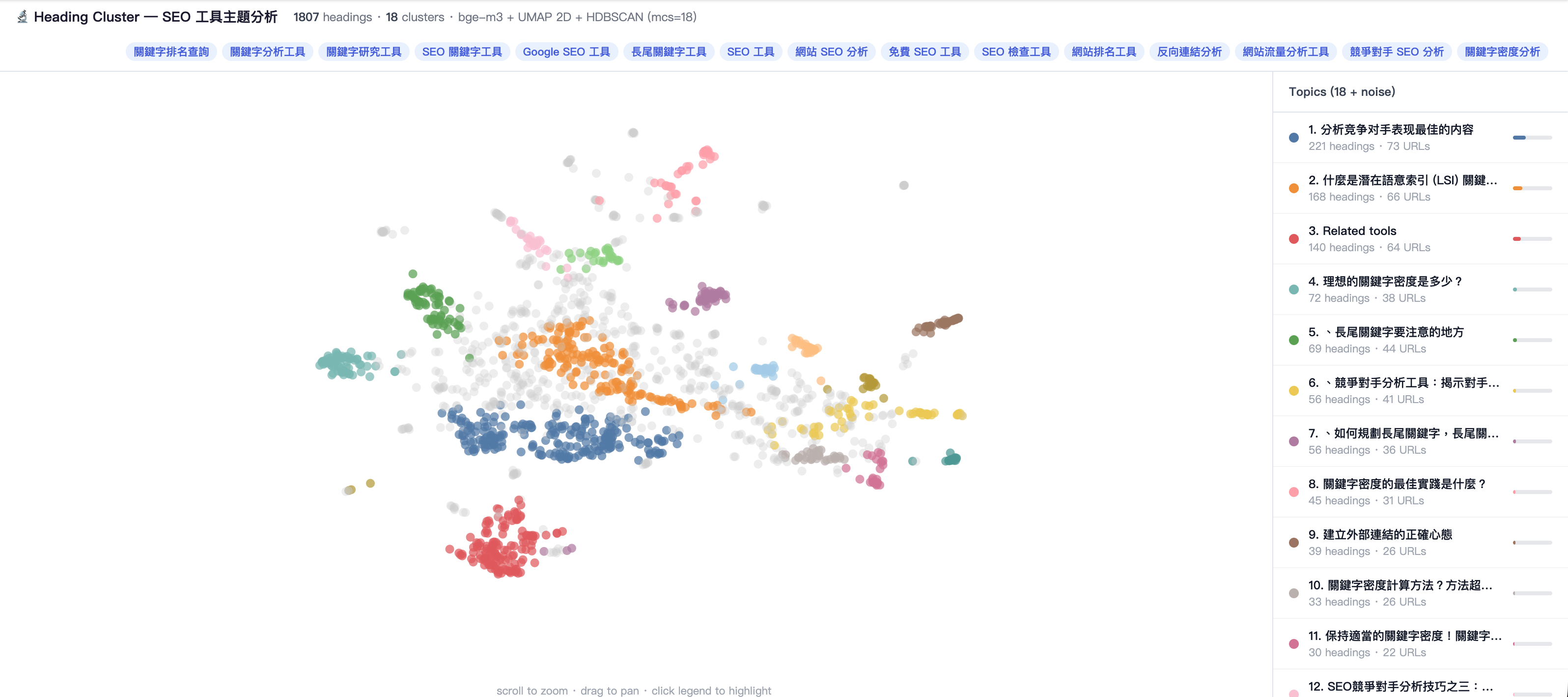
為什麼 GEO 更難
到了 GEO,事情就開始不一樣了。
傳統 SEO 裡,我們常常處理的是 keyword。即使 keyword 有變體,它通常還是相對固定的字串,例如「SEO 工具」、「免費 SEO 工具」、「網站 SEO 分析」。
但在 GEO 的情境裡,query 更像自然語言問題。每個人問 AI 的方式都可能有微小差異:
- 有沒有推薦的 SEO 工具?
- 小公司要怎麼選 SEO 工具?
- 如果我想做內容優化,哪些工具比較適合?
這些問題彼此不完全一樣,但它們背後可能很接近。也正因為如此,我一直在想:如果還是用傳統 keyword 的方式去看 GEO,可能會漏掉很多東西。
對我來說,GEO 的難點不只是「答案會變」,而是 query 本身變得更鬆散。傳統 keyword 還比較像固定標籤,但自然語言 query 更像一大片彼此相似、卻又不完全一樣的問題雲。
GEO Query Clustering
所以我現在比較感興趣的方向是:能不能先把大量 query 用 embedding 做 clustering,再回頭研究不同 cluster 的 AI 回答與引用來源?
如果可以,這樣就會有幾個好處:
- 比較不會被單一 query 綁架
- 比較容易看到一整群相近意圖的共同模式
- 可以開始區分「組內很像」和「組間差很多」的情況
換句話說,傳統 SEO 比較像是「先有 keyword,再去研究 SERP」;而我現在想做的 GEO 實驗比較像是「先把 query 分群,再去研究 AI 如何回應這些群組」。
這裡真正有趣的地方在於:如果 embedding clustering 真的有用,那它可能會讓 GEO 的研究方式變得比較穩定,而不是每次都靠直覺挑幾個問題來測試。
而且這裡我最在意的,不只是 query clustering 看起來漂不漂亮,而是它能不能被驗證。
我現在打算驗證的方向比較明確:
- 組內 SERP 相似度 是否真的比組間高
- 組內 AI Overview / AI 回答相似度 是否真的比組間高
- 如果這兩件事都成立,那至少代表這種 clustering 不只是視覺上看起來合理,而是對後續研究真的有幫助
所以我之後想做的,不只是看 scatter plot,而是把這些 cluster 拿去跟 SERP 與 AI 輸出做對照,確認它到底是不是一種有效的整理方式。
這張 bubble view 對我來說就很有意思。因為它讓我從另一種角度去看同一批 heading:不是看單一 heading,而是看 topic cluster 的大小、邊界和彼此距離。
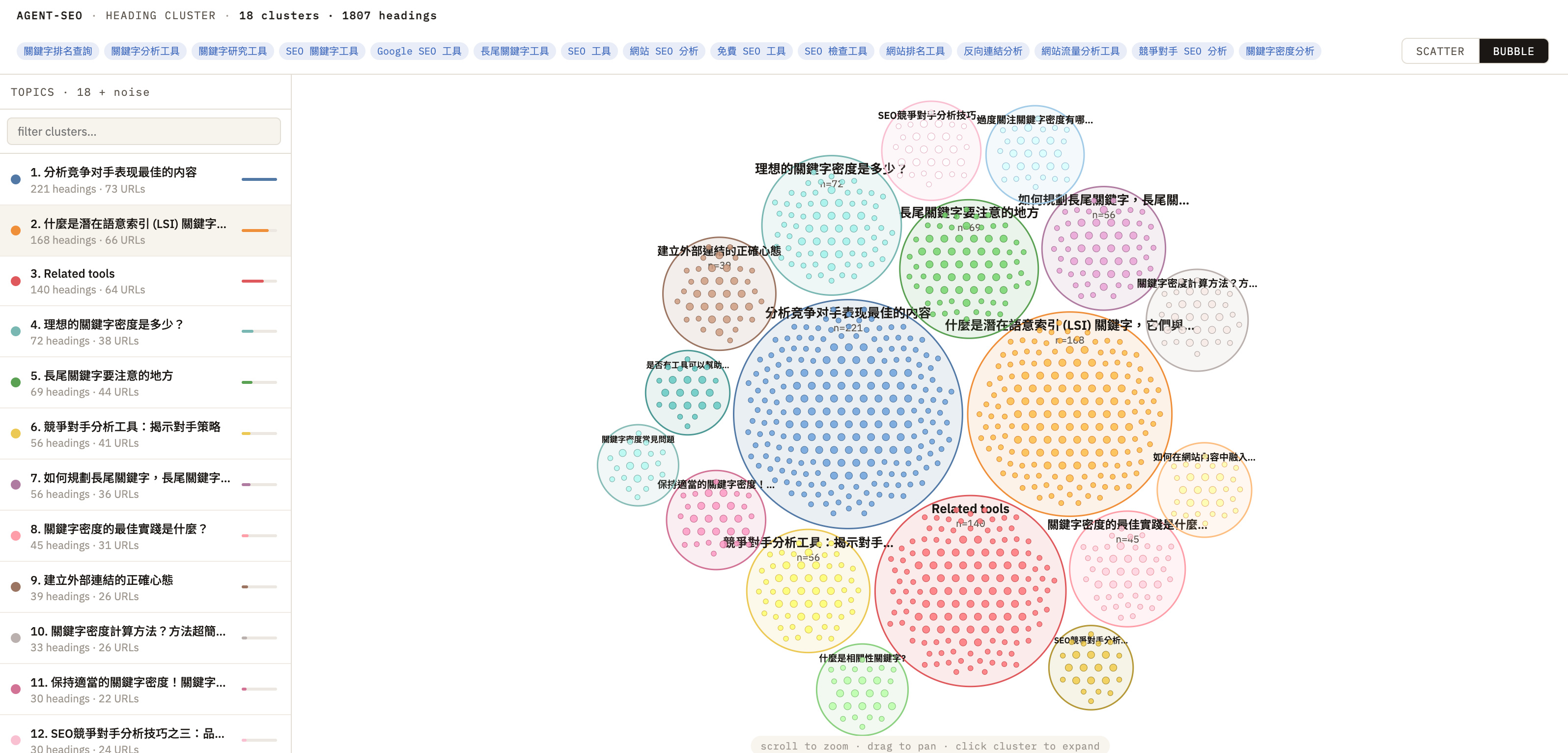
我想驗證什麼
我目前最想驗證的不是「這個工具能不能做出漂亮結果」,而是幾個更基本的問題:
- embedding clustering 出來的群組,是否真的符合人類對搜尋意圖的直覺?
- 不同 cluster 之間,AI 回答與引用來源的差異是否比組內差異更大?
- 如果答案是,那這種方法是否可以幫助我更有效率地做 GEO 實驗?
這裡之後可能會需要更正式的比較方法,例如觀察組內相似度、組間差異,甚至用更嚴格的統計方式去確認分群到底穩不穩。
但在那之前,我想先做的還是比較務實:挑幾個主題,真的一組一組去看,確認它是不是比單純靠經驗判斷更可靠。
換句話說,我現在不是要證明「我找到最好的 clustering 演算法」,而是想先確認:這條研究路徑值不值得繼續走下去。
寫在前面,也寫在後面
這篇還不是完成報告,比較像一張研究地圖。
對我來說,SERP overlap clustering 讓我確認了人和 AI 可以怎麼一起工作;而 Heading Clustering 和 GEO Query Clustering 則是在往下一步走,試著回答內容研究和 AI 搜尋研究裡更細的問題。
如果前一篇文章在談的是 HTML review mode,那這一篇比較像是在談:當我真的開始把 AI 工具和資料方法接起來之後,接下來還有哪些問題值得被拆開來研究。
而且我現在也滿確定,這不會停在「想法紀錄」而已。接下來我會想直接拿一篇部落格當實驗場,真的去驗證這些 clustering 結果,到底能不能幫我更穩定地整理內容結構與 GEO 問題。

